A while back in the lab we were conducting an experiment that involved passing a laser beam through a narrow iris, using a beamsplitter to take half the intensity of the beam and send it one way, with the remaining half passing through undisturbed. Then we arranged our mirrors in such a way as to bring the beams together so they were propagating in the same direction parallel to one another before doing some jazz that will hopefully make an interesting journal article.
To get a good handle on calibration, we wanted to characterize the two parallel beams. Laser beams, despite how they might look to the naked eye, are not pencils with zero light outside the beam and uniform intensity within. Instead, they often (but not always) follow a Gaussian profile. Their peak intensity is at the center of the beam and uniformly falls off away from the center. However, in this experiment we can't guarantee that we split the intensity exactly 50:50, or that aberrations in our equipment haven't made one of the beams a little wider than the other. So while in a perfect world the two identical beams might look like this projected on a wall...

...in practice the two non-identical beams might look something more like this:

The definite way to characterize something like this is with a device called a beam profiler, which is essentially a specialized camera. But they're expensive, fragile, and finicky. We took a shortcut. We put a razor blade in on a translation stage so that we could gradually move it to the right and cut off first one beam, then both beams. While doing this, we measured the total power as a function of how far over we had moved the razor. A picture might help. With the razor at (say) the position x = -2, the beams as they hit the power meter looked something like this:

So everything to the left of the razor edge is cut off. By assuming that the beams are in fact Gaussian (with possibly different amplitudes and widths), we can calculate that the power not blocked by the razor and thus hitting the meter is:

Where erf is the error function, the "a" coefficients are the amplitudes, the μ are the beam positions, the σ are the beam widths, and c is the background signal of the detector. For the values I picked in the uneven-beams example image above, the graph of this function looks like this:

In our experiment, we have to do that backwards - extrapolate the various constants using the power vs. razor position measurements. Here's the data we actually had, with the y-axis in mW and the x-axis in microns:

From that graph, it's possible to eyeball things and make guesses for what the parameters might roughly be. Just a few decades ago that would have been just about the only possibility. But today, computer algebra systems (Mathematica in this case) can take a starting guess for the parameters, calculate how far off that guess is, create a new guess, and iterate until a numerical best-fit is found. This would take a human probably weeks with pen and paper, but a computer (my netbook even) can do it in about a second. The best fit in this case is:
a1 = 6.45147, a2 = 6.97507, μ1 = 1575.7, μ2 = 3656.74, σ1 = 370.544, σ2 = 294.698, c = 0.438761
So we know the relative powers of each beam, and how far apart their centers are (about 2.08 mm). Here's the fit, superimposed on the points:

It's not perfect, but it's plenty good enough for what we needed.
As something of a philosophical aside, scientists (physicists especially, and I include myself) like to say falsifiability is one of the major defining parts of the scientific enterprise. If a theory is at variance with what is actually observed in reality, so much the worse for the theory. But here I have presented a theory in the form of that P(x) equation, and in fact it fails to fit the points perfectly. Is the theory wrong? Well, yes. The beams may not be perfectly Gaussian. Even if they are, the simple model treating the razor as a diffraction-free cutoff is at variance with the full Maxwellian treatment. Even if it weren't, the theory I'm testing also implicitly includes the "theory" of imperfect lab equipment. When falsifying a theory, it's often not easy to say what exactly you've falsified. And so philosophers of science write books on this sort of thing, and physicists devise ever more careful experiments to disentangle theory from approximation from equipment, and everyone stays pretty busy.
Rather a lot of words from a 5-minute "we'd better double check our beam quality" measurement, but what else is the internet for?
- Log in to post comments
More like this
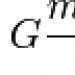

One obvious check on the quality of the model would be to repeat the test in the vertical direction. You will get different results for the μ's, but the a's and the σ's should be very nearly the same as before if the azimuthally symmetric Gaussian model is a good approximation. For that matter, μ1 and μ2 should come out nearly equal, if you did your alignment right.
Not sure how your optimisation code is converging on the fit paramaters, but if you have some control over things, I would suggest you try using l1 rather than l2 norms in your code. That is, instead on minimising the RMS differences between the curve and fit points, you could try simply minimising the sum of the absolute differences.
The reason this sometimes gives and improvement is because of the nature of the l2 norm when the differences becomes small. Small differences become even smaller when squared, so the l2 norm tends to leave a lot of small but noticeable errors around. By contrast, the l1 norm (abs(d)) tries to minimise errors in a more evenhanded way once the fit closes in on a good solution and the differences all become small.
Well, one or more obvious hypotheses likely falsified is that we observe separated beams in quantities of one, three, four, ...
Or conversely, Springer's razor tells us that we see two beams. :-D
We find it useful to make a numerical derivative of the data before fitting. This should give you the gaussians directly, that are much easier to visually check and treat mathematically.
On the other hand, I completely agree on the falsifiability paragraph. It's oh so hard to be sure that the theoryis what's wrong, and not any of the very very long list of things that could go wrong in an experiment. But, hey! That's one of the reasons science is interesting!
Tora Bora in particular was a cluster fuck and should simply not have happened.